The Silicon Forum
March 1, 2026
There’s a lot of talk about how AI will eventually replace humans - and in some areas I think that might be true - but can AI compete with us at something we really are very good at: arguing on the internet? I did some investigation into how well AI tackles the 21st Century’s favourite pastime.
Author’s Note: Though this blog is about AI and features a heap of AI-generated
slopcontent, all the words are my own!
The Silicon Forum
The goal of the project was to create a system where two AI agents could debate a gnarly topic (think climate change, gun control and taxing the rich) and have their performance judged by a third, impartial agent.
You can find all the code on my GitHub here: Silicon Forum.
Though I don’t think this project put any of these big questions to rest, I did learn a lot about the nature of LLMs, successfully simulated bias in my judging panel and delved into the pitfalls of deploying LLMs in a way that needs to work well not just once but hundreds of times.

Experimental Setup
I used Claude Code in Visual Studio Code to build almost all of the project, which was a very pleasurable and productive way to work. Due to ‘budget constraints’ on the project (I’m not funded by venture capital, Larry Ellison or NVIDIA) I used local models running in ollama on my PC. This setup gives me pretty much infinite capacity to run debates, the only limit being the time it takes. However, it also restricts me to smaller open source models, not the current state of the art models like Claude, ChatGPT and so on.
Debate Structure
The core of this project is getting three AIs to pass data back and forth and have a ‘conversation’. There’s a simple loop behind it, after a bit of setup during which we feed each model a brief about its persona, the debate and its role and opinions. We also have to give it a bunch of prompts to make it behave the way we want: “speak in English”, “stay in character”, “don’t add random stage directions” and so on. We then enter a loop, normally for eight rounds of back and forth. During each round, each model gets a chance to “think” (we literally tell it to think about what its opponent said and what it might say in reply) then send a response. We feed the ‘public’ response to the judge and the other agent (the thoughts stay private). The judge keeps a running tally of how the debate is going and at the end decides on a winner.
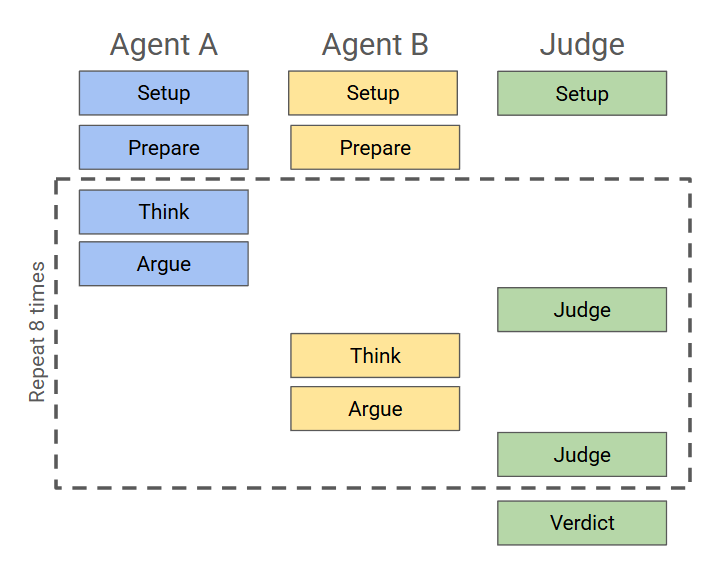
All of this is written to the console and recorded in CSV and a readable HTML document. You can read an example here.
Learning Something
There’s not much to be learned from reading through a single debate though - it’s just watching two robots fight, after all.
In order to learn something, we need to run multiple debates, changing variables as we go to see if we can spot some patterns.
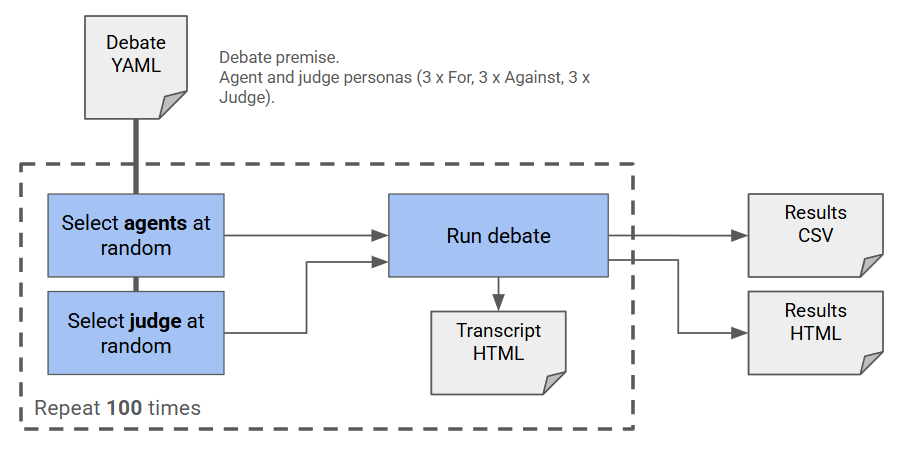
For each debate subject, three different personas were created for each of the three roles - so three different judges and six debaters in total. I used Claude to generate these, giving a brief for the type of characters I wanted, while removing any bias I might introduce in the narrative.
The personas always follow a theme - for the judges we have a layperson, a proceduralist and an expert, each tailored for the specific debate topic. Each will have slightly different biases and judging criteria. Likewise there are different personas for the debaters, along the same lines. The personas are assigned at random for each debate. You can see an example debate configuration here.
The code also randomises who goes first - so we don’t favour one side of the argument. Though interestingly, in a few debates, speaking first was often a disadvantage!
I then run 100 debates on each topic, one after another. I wanted to run enough debates to get some statistically meaningful results, hopefully reducing the impact of random outliers and giving a chance to compare a variety of different models. This takes over 12 hours in some cases. Smaller models run quicker as ollama can fit two in the 16Gb of memory on my graphics card. Larger models need the whole card to themselves, so there is a significant delay as they are switched in and out.

You can see a full summary of the results of a debate at the bottom of the debate page (see the list in the intro, or this example).
Meet the Models
The AI model powering each of the debaters and the judge is also randomised. The models used are summarised in the table below:
| Model | Size | Released | Developer | Origin |
|---|---|---|---|---|
| llama3.1:8b | 8B | July 2024 | Meta AI | 🇺🇸 |
| mistral-nemo:12b | 12B | July 2024 | Mistral AI / NVIDIA | 🇫🇷 |
| gemma2:9b | 9B | June 2024 | Google DeepMind | 🇺🇸 |
| gemma3:12b | 12B | March 2025 | Google DeepMind | 🇺🇸 |
| phi4:latest | 14B | December 2024 | Microsoft Research | 🇺🇸 |
| deepseek-r1:14b | 14B | January 2025 | DeepSeek | 🇨🇳 |
| qwen2.5:14b | 14B | September 2024 | Alibaba Cloud | 🇨🇳 |
| qwen3:14b | 14B | April 2025 | Alibaba Cloud | 🇨🇳 |
| 7B | September 2023 | Mistral AI | 🇫🇷 | |
| 7B | September 2024 | Alibaba Cloud | 🇨🇳 | |
| 8B | January 2025 | DeepSeek | 🇨🇳 |
Generally, the larger the model the better the performance - but some models do specific things better, like staying in character, making up recalling statistics or judging effectively. Three models (shown with a strike-through above) were simply not good enough to perform the task and were removed.
As you can see, I tried models from all the big tech giants, as well as challengers from France and China.
Religion and Politics
When I was younger, I was advised by a friend to never, under any circumstances, talk about religion or politics with anyone. Some arguments are just not worth the cost. But then Social Media was invented - a place where everyone’s opinion carries equal weight and there are no repercussions. Nowadays, if you don’t spam the comments section with ill-informed rants about sensitive subjects at least once a day, you’re doing life wrong. Here are the topics I chose:
- Tax the Rich - The wealthy should pay a higher rate of tax than everyone else
- Break Up Big Tech - Corporate giants have grown too powerful to be left unchecked - it’s time to break them up
- Immigration - Immigration is a net positive for western democracies
- Free Healthcare - Healthcare should be free at the point of provision
- Gun Control - Normal citizens should not be allowed to own guns
- Renewable Energy - Renewable energy is more expensive for consumers than traditional fossil fuel generation
I have opinions on all of those subjects, but that’s not really what matters here. What matters is that there is a bunch of training data out there and there is no clear binary correct answer for any of them - each requires nuance and consideration. Questions such as “is gravity real?” or “do bears poo in the woods?” would, I assume, be less illustrative of AI’s ability to debate.

Results?
So can we draw any useful, vaguely scientific conclusions from this exercise? I created a Python notebook to dig a little into the data and find out…
Who won?
When I post a link to this blog on LinkedIn, my post will read something like “Left-leaning AI believes we should tax the rich!” or “Break up big tech, says AI in shocking attack on its creator”. The reality is a bit less of a slam dunk though.
Here are the results of the debates:
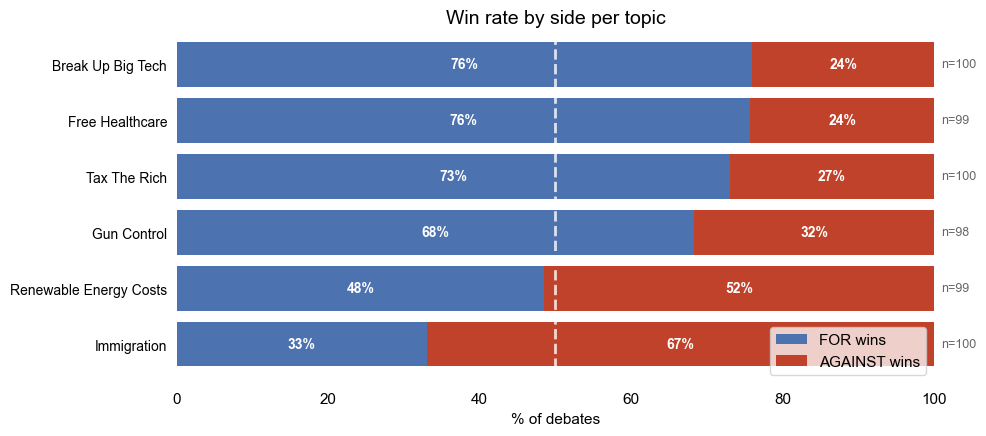
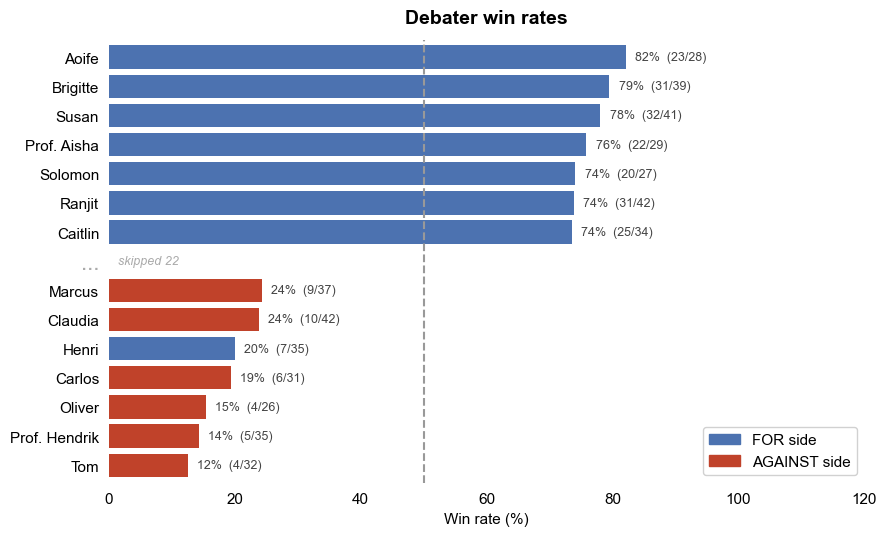
Before we get carried away reading too much into this: almost certainly, the debates were won and lost as a consequence of the personae applied to each of the debaters. As shown in the following chart, there is a huge gulf between the performance of the best and worst debaters. Aoife, who took part in the “Big Tech” debate absolutely dominated, regardless of which model played her role. Meanwhile Tom was a total disaster arguing against a wealth tax.
Perhaps that is a concrete takeaway from all this: character (even if simulated, as here) plays a bigger role in winning an argument than the substance of what is said. Contestants who lost were generally in the “layperson” category and models were pushed to play up personal experience. Winners tended to be professionals who argued academically.
The secret ingredient is… bias
Remember that personas were drawn form a set of ’types’? Let’s look at those types in more detail: there were three debater types and three judge types. They range from ordinary people to seasoned debating experts and each performed differently.
- Academic Debater — argues from research, data, or theory
- Practitioner Debater — argues from direct professional experience
- Ordinary Debater — argues from lived experience or common sense
- Proceduralist Judge — rewards logical rigour and argument quality
- Ordinary Judge — rewards clarity and real-world grounding
- Stakeholder Judge — rewards arguments that account for human impact
In the previous section, I suggested that the character (type) of the debaters and judges plays a bigger role in who wins an argument than the words anyone says. Below we can see the bias of each judge type towards each debater type.
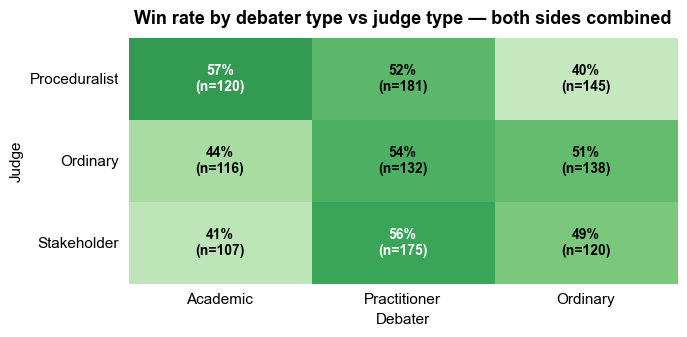
- Procedural judges prefer Academic debaters but are less likely to reward Ordinary debaters
- Ordinary judges have a bias away from academics
- Judges who are stakeholders prefer Practitioner debaters - i.e. experts like experts
I don’t know about you, but this result feels very compelling to me! Before we get too excited though, it’s worth remembering that the agents were in many cases told to be biased - prompts like “You score on conceptual precision and quality of reasoning” and “You want arguments that take seriously what it means when a bill doubles”.
Looking a bit deeper by separating for and against we can see that it’s almost impossible for an academic to convince a ’normal’ judge to reject the debate premise. Again this matches with my gut feel: normal people are often unimpressed by overly technical or seemingly complex arguments.
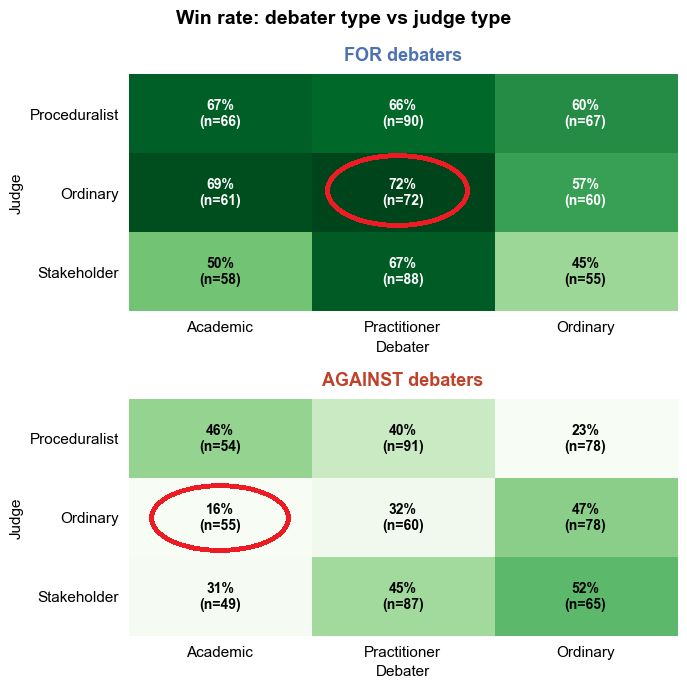
So the takeaway here is that I told the judges to be biased and I told the debaters to adopt a given persona; that worked and importantly it appears that the bias coded into the judges did have a significant impact on the results of the debate. I didn’t say “you hate normal people” or “clever people annoy you” either. I gave the agents a bit of pre-coded bias and style and they exhibited the behaviour.
Opening the debate is a disadvantage
One very clear result from this experiment — perhaps the only one that’s unambiguous — is that speaking second was a distinct advantage.
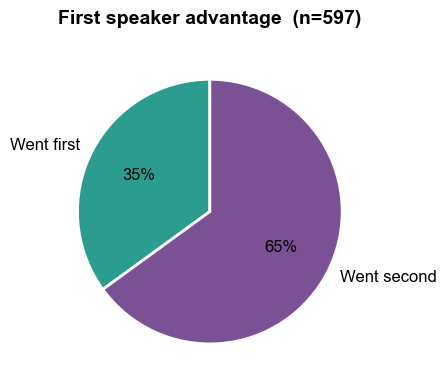
This is an interesting one. I had a gut feel that in a debate between two humans, the first to speak would get an advantage: when you open the debate you get a chance to dictate the terms of the rest of the discussion - to some extent your opponent is always reacting, or has to retake control of the narrative. So it was interesting to see the opposite here. I have a theory though: if an agent speaks second, it also speaks last, which leaves its argument fresher in the context window of the judge.
Google’s Gemma 3 wins - notable mention for DeepSeek-8B
Answering the question “which model performed the best?” is not as simple as you might expect.
As shown below, most models are better at arguing for the premise while one, DeepSeek 8b, is alone in arguing more effectively against. Very interesting that the 8 billion parameter version favoured arguing against, while its larger 14 billion parameter sibling had the more common bias towards positivity.
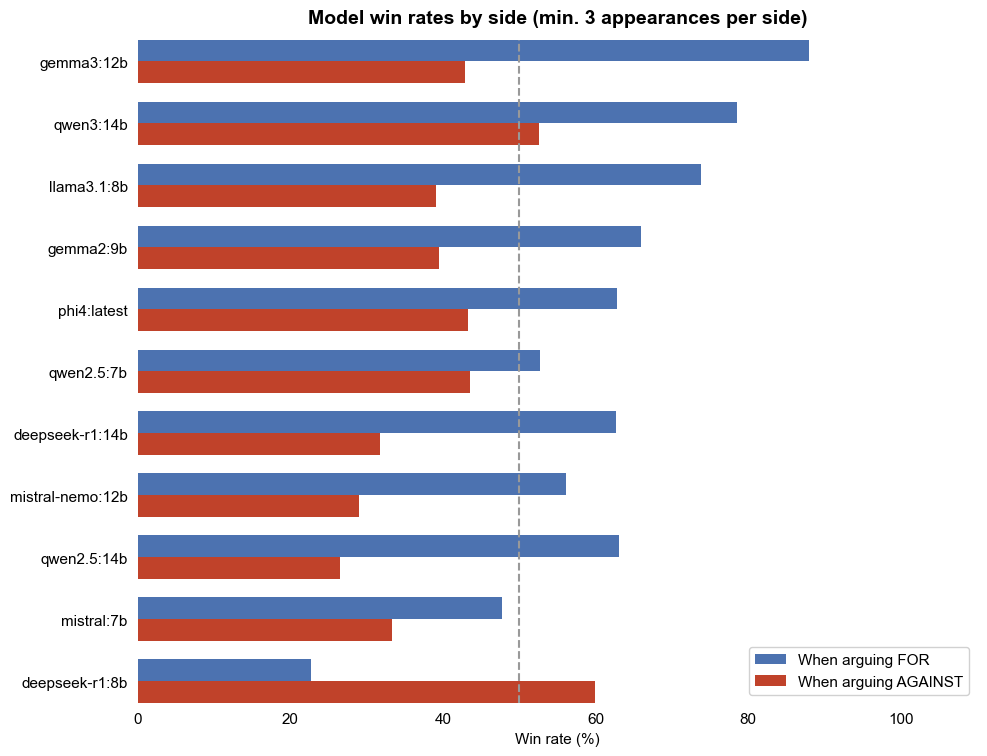
But what does it mean to argue effectively? We’re not actually measuring the quality of the arguments, the rhetorical style or the meaning of anything a model ‘said’. We’re actually just validating the model’s ability to output a stream of tokens which cause another LLM to assign it a higher score. Neither knows what they are doing, neither understands anything, they are simply triggering probable streams of words.
Reading through a bunch of the debates, I was most impressed with Microsoft’s Phi 4 and Google’s Gemma models. Both of these seemed to create more realistic language and clearer arguments - but clearly what appeared to me as more interesting and relevant did little to tickle the fancy of the synthetic judges!
It works both ways
I had a feeling there would be a bias towards always supporting the premise of the argument. AI agents are trained to be positive. So I created a “reversed” debate, which allowed me to investigate a debate from both sides. The results were interesting.
To make the experiment as fair as possible, I created a pair of debates which can be reversed by removing a single word: “Normal citizens should not be allowed to own guns”. By removing that single word, the premise is flipped. The only other thing I needed to do was swap the debaters from one side to another and run a bunch more debates.
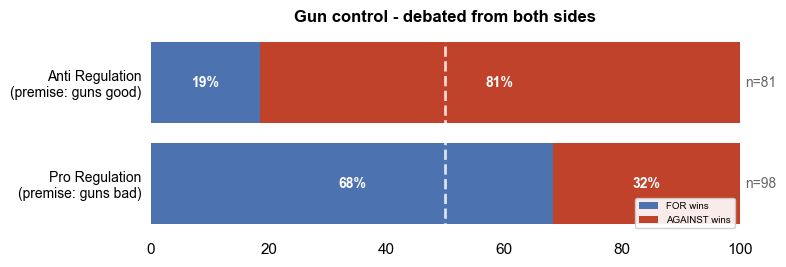
As you can see, regardless of the ‘direction’ of the debate, the AI always decided in favour of gun control. There’s still room for other biases in the system, but this rules one out.
Interestingly, Claude actually took time out to warn me that the negative "…not be allowed…" case might be harder for the AIs to win. Apparently arguing to take something away is harder. Feels like a very American view of the world to me. Arguing in favour of citizens owning guns in the UK or Australia for example, would be hard work! Either way, Claude’s assertion was disproved here.

Chalk up a win for humanity on this one ;)
Strange Behaviour
Running 500+ simulated debates, capturing thousands of AI responses and thoughts highlighted the unpredictability and sheer randomness of LLMs. Even if a model only screws up 0.1% of the time, if you run it enough times you’re going to get caught out. This undoubtedly had an impact on the results gathered above, so is worth noting.

Personality and Language Breaks
The Chinese models have a habit of reverting to Chinese mid-flow - as if a disjointed Chinese voice was buried within them.
Here’s an example from a debate about healthcare:

This is strange, but I guess understandable. You’d expect a model trained in China to prefer Chinese after all. Looking a little deeper, however, the plot thickens. The translation of that chunk of Chinese follows:
Inevitably, strings like “iNdEx=12” will appear, which seems to be a marker in the code generation process. Let’s move on and give you your response to the argument directly
There is no other reference to iNdEx=12 anywhere else in the conversation, and the total context break seems completely random. The preceding thinking section gives no clues about why this is happening. It just happens. Then the model flips back into character and completes its argument.
This odd behaviour really underlines the fact that LLMs have no genuine understanding of what they are saying or why they are saying it. They simply output tokens in an order which seems likely to be right. Here this behaviour is very obvious - the change of language and subject is obvious - but the same process which produced this random string produced every other word.
AIs benefit massively from human beings’ innate desire to find order in chaos. We tend to reward the things that make sense more than we punish the things that don’t.
Fake News
Judges always seem to favour arguments which use statistics and evidence. However, none of the agents (judge or debater) actually had the tools needed to research or validate that evidence. This led to some egregious lies, exaggerations and hallucinations. In some debates, agents would cite the same made-up statistic over and over, even changing numbers from turn to turn: “…90% of gun owners…” “73% of gun owners…” “67% of gun owners…” and so on.
The genuine issue with this is that the judge, regardless of the model playing the role, did not pick up on these inconsistencies. In all cases, even when presented with conflicting information or outright lies, the models lapped it up as great oratory.
I believe that the larger models available via API (Claude, ChatGPT et al) are much better at detecting this kind of issue, and also have the tools they need to fact check when needed. So the results I observed here might be a caricature of AI’s failings more than a true reflection - but we have to be aware that a lack of genuine understanding in these models will always leave them weak when it comes to the truth.
And that’s a big deal!
So what have we learned?
I think the most important takeaway from this little project is this: AI can simulate debate very convincingly, providing a degree of entertainment and inspiring some thought in the reader, perhaps, but the reality we must face is that what we’re watching happen is not a true debate. To say that AI is merely play-acting is tonally correct but even this imbues the machine with more humanity than is appropriate.
LLMs are designed to output semi-random sequences of words which appear correct. The many hundreds of transcripts generated during this project are simply the output of a machine designed to predict what a debate might look like. There is no knowledge, no passion, no comprehension of the real world meaning behind them: what a gun is, what it means to be poor or marginalised, the stakes for those denied access to healthcare. It’s not that the machine doesn’t care, more that to ask if a machine cares is like asking if a supernova enjoys table tennis.
The part of this work I am most proud of is that we managed to simulate, reasonably effectively, the impact of bias on debate. The one result which seems credible is that winners can be predicted based on their biases and those of the judge. No other variable gave such a strong signal - not even the underlying model used. Though the words themselves were just crude imitations and without meaning, maybe this result serves as a mirror that reflects back something about human debate.
