World's Simplest Data Pipeline?
November 13, 2022
Data Engineering
Data Engineering is very simple. It’s the business of moving data from one place to another - usually the emphasis is on moving data into your business from external sources, but data engineers also manage outgoing data feeds, integrations, platforms and APIs and the transfer of data between internal products and systems.

To be successful, your data engineers need to care about:
- Fidelity: how reliably can data be transferred and stored without corruption or loss?
- Capacity: how much data can be moved and how quickly?
- Reliability: how well can systems recover from outages and incidents?
- Speed of execution: how quickly can you get a new data source up and running?
A solid data engineering capability is a huge enabler for any business, as I’ve covered in a previous post, because it gives you the confidence to scale your business quickly, build new data-driven products and use analytics to answer questions quickly and confidently. For me, the last point about development time is by far the most critical to success.
How much you invest in your data engineering capability is dependent on your own ambition and needs and the risks of over- or under-investing are well documented. I believe there are some rules and guidelines that are universally applicable, regardless of your team size or tech stack, and that following these rules can save huge headaches in both teams of one and teams of one hundred.
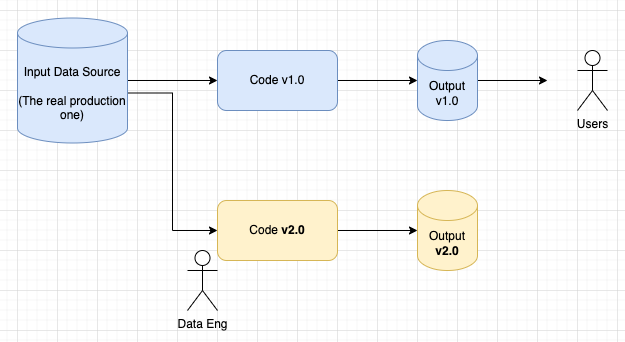
In order to demonstrate this, about a year ago I built the simplest data pipeline I could build while still adhering to my rules. I’ve left it running on my personal AWS account since then, during which time it’s been gathering data and hopefully proving my point. If you want to play along at home, you can find all the code on GitHub.

The Rules
Before we start, let’s summarise my golden rules for solid data engineering.
- Idempotent Operations - all processes and transformations are deterministic and repeatable.
- Immutable Data - write only. No deletes. No updates. Ever.
- Simple left to right flow - separation of concerns, single responsibility principle.
- Schema on write - assert your schema as you write data, not when you read it.
- Fail fast - don’t try to code around errors or schema changes in advance.
The mechanisms for driving and measuring quality in Data are very different to those which work for traditional software development. When building a new web service, it is possible to wrap it in unit tests, CI and CD pipelines and deploy it to production with a high level of confidence that it will work. This is possible because the vast majority of the behaviour of that system is embodied by the code itself. With data pipelines, the behaviour of the system is dependent on both the code you deploy and the data it interacts with (schemas, data types, constraints, volume, unexpected values etc). So traditional unit testing of data systems can be a waste of time - it simply doesn’t give you complete confidence.
A better workflow for data product development is:
- You build the code
- You run the code using real input data
- You analyse the quality of the output data
- You release the code and the output data to production.
This workflow is incredibly powerful but requires all of the above to be true - you need the job to be idempotent and deterministic so you can run it again. You also need the data to be immutable, with no updates or deletes so you can control its release and versioning in tandem with your code. Asserting the schema of output data on write, as part of the deployed code also helps with this versioning and release cycle, defining your contract for data transfer alongside your business logic.
Note that this way of working means data teams often follow a different process for promoting their code up through environments from dev to prod. That doesn’t mean a lack of rigour, just a different approach to segregating production and test datasets and code. Bugs in data pipelines manifest differently too - if a user transaction fails on your front end, it just fails. They can try again or phone customer support, but you can’t alter what happened. With data pipelines, if faults are discovered they can be fixed retrospectively - code around the problem, re-run the pipeline, deploy the fixed data to production. For this reason, it is better for pipelines to fail immediately on error, rather than being complicated with swathes of error handling code. Similarly it’s best that updates and deletes to data in-situ are avoided, so mistakes can be rolled back.
Anyway, this is getting too philosophical, and I just wanted to show off my little data pipeline, so…
Weather Data
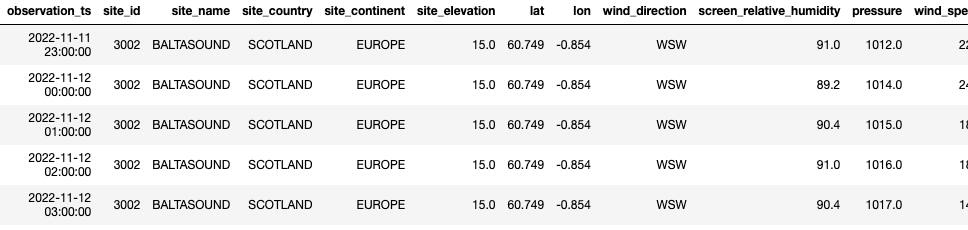
In the example code, I pull data from the Met Office DataPoint API, which provides 24 hourly weather observations in real-ish time.
The DataPoint API is a great example of many of the shortcomings of the kinds of APIs you meet in real life. When you call the API you get a set of hourly readings for the last 24 hours. If you call the API at 2:37pm, you’ll get data from 3pm the previous day to 2pm today. There’s no way to query further back, so if your process fails for more than a few hours, you’re losing data with no recovery path. The format of data you receive is a complex JSON document which seems to be optimised to suit the design of the source system, rather than the consumer.
This isn’t a criticism of the API by the way, it’s designed to be a real time feed of current weather conditions and it’s wonderful that the Met Office make it available for free to developers. There are many APIs like this in the wild that past teams have, for whatever reason, been forced to use to gather business critical data in situations where reliability and fault tolerance are critical.
The goal with my simple data pipeline is to load this ‘difficult’ data in a way that maintains high fidelity and provides a sensible recovery mechanism when things go wrong - which happened to me more than once!
How the ETL pipeline works
Data is currently pulled by a Python ETL, within a Lambda function in AWS. The function is triggered by a cloudwatch scheduled event just before midnight each night. The output of the ETL is pushed to S3 in a more queryable JSON format for use with Athena, which is the smallest and cheapest query solution I could find!
Critically, the lambda function also saves the raw input to a separate S3 bucket for replay and to deal with errors.
Finally, once data is loaded to the destination bucket, the function will update the relevant glue partition, ensuring data is queryable as soon as it is added.
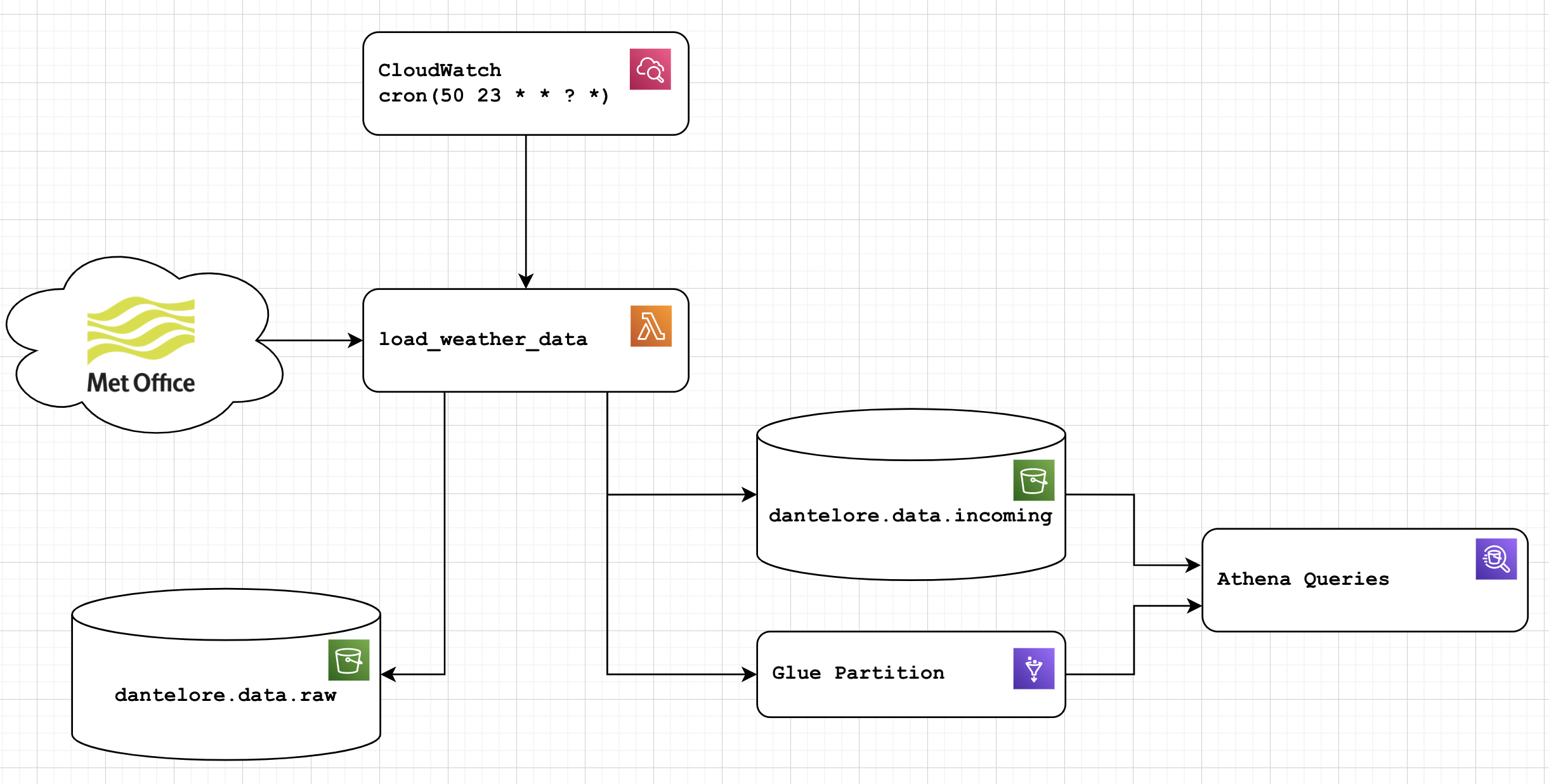
This simple ETL gets you as far as usable data in S3/Athena, which is the first tiny step to building a data platform in AWS. Using this raw incoming data comes with risks though - you’re likely to see duplicates, missing fields and perhaps even schema changes over time.
The data is (deliberately) stored with a schema matching the domain from which it came: in this case the schema of the weather data is quite Met Office specific. If we wanted to pull in data from other sources (Meteo or the WMO for example), different ETLs and different schemas would be used. A downstream job could then be written to munge all these different sources into a single consistent model of weather data worldwide - but this shouldn’t be done in the ingest layer as it adds complex dependencies and business logic we don’t want or need at this stage.
Dealing with Failures
In terms of stability, calls to the API have been very reliable. Since I am not “on call” for the pipeline, there’s little I could do to deal with an outage anyway, over and above a few retries on the lambda. In practice, the most common source of failure I saw was with the JSON data. Though JSON is a standard, there are subtle differences in the way different languages and tools interpret the spec. I was caught out a few times with array properties - it’s easier to show the workaround than explain the problem, so:
obs = p.get('Rep')
if not obs:
print(f'No observartions found for {site_id}: {site_name}')
obs = [] # Better an empty list than None
elif not isinstance(obs, list):
obs = [obs] # I'd prefer a list of one item, not one item!
Easy enough to code around, but this formatting issue evaded me for days and caused the script to fail and no data to be loaded. The reason I didn’t loose data permanently is because I’d implemented the raw bucket. All source data is stored here before any processing and in its original format. This raw source data is archived as the ultimate “get out of jail card”. Once I’d updated the code to deal with the weird array properties in the JSON, I was able to backfill all the data with a simple script, using the archived source data as input.
This works because data in S3 is immutable and is never updated or changed; my transformation job is idempotent - I can run a given version of it again and again and get the same output; my script fails fast - if it can’t process the input, no output is stored. Most importantly, the flow is strictly left to right - data is downloaded then processed then stored.
This pattern has got me out of a huge number of sticky situations in the past. The knowledge that everything downstream of the raw source data can be regenerated at will is a great insomnia cure.
Schema Validation
It makes a lot of sense to validate data written to the data lake bucket against a JSON schema. The glue schema here is managed directly by Terraform, meaning it is explicitly set and linked (via git) to a specific version of the ETL. This is basically an implementation of schema on write, where you validate data before you write it to the lake, rather than worrying about it every time you query. There are technologies (e.g. Glue Crawlers) which offer schema on read capabilities, but as I see it, this introduces the opportunity for uncontrolled change after your ETL has run and the data has been written. Much better to be explicit, in my opinion.
I wrote a function to do some schema validation for the demo, but it’s pretty slow, and since I am paying for this with my own money it’s commented out. In a real system, it makes sense to do this - either within the ETL, the ETL framework or a separate component in the architecture/flow. Being able to guarantee that all data fits a known schema is very valuable!
def validate_json(data_filename, schema_filename):
with open(schema_filename, 'r') as schema_file:
schema = json.load(schema_file)
with open(data_filename, 'r') as data_file:
for line in data_file:
obj = json.loads(line)
jsonschema.validate(obj, schema)
Of course, data feeds change, new fields are added and data types tweaked and you’ll need to make code changes to support those. I would be willing to bet that you’ll see much less disruption and cost associated with managing those code changes than you would if the schema changes were allowed to percolate through to data consumers in an uncontrolled way.
Scalability and Dev Time
It’s hard to demonstrate scalability with a simple (and cost effective) demo. It’s even harder to demonstrate developer experience and cycle time when you’re coding alone in your spare time!
Suffice it to say that every AWS service I use here is 100% serverless and horizontally scalable. Lambda, S3, Glue and Athena are essentially unlimited in their capacity. “Aha!” I hear you exclaim “you’d never use these tools in a production system”. Well, yes, this is a simple demo, but the general rule still applies: use scalable SaaS offerings where possible. Airflow via MWAA; Confluent Cloud over roll-your-own Kafka; Snowflake over RedShift (accepting that Athena and BigQuery probably work for 90% of your needs); Lambdas and API gateway over managing servers. In this day and age there is no reason you should ever need to manage your own buzzing metal boxes or even virtual machines.

In terms of time to market, this demo took me a couple of days to design, code and debug, spread over a couple of weeks in my free time. Again, in real life you might use beefier tools, but leveraging Python along with liberal helping of libraries and cloud tech is absolutely the best way to achieve capacity and delivery time aspirations. You want your team to be focussed on the unique, differentiated aspects of building a data platform, rather than wheel reinvention or excessive boilerplate coding.
There is no better way to solve software problems than with code - and systems which promise to do this via a user interface or config file will often disappoint. That said, if you’re pulling a known dataset from a business system (Jira, Zendesk, Lever, Survey Monkey…) and are happy to rely on someone else’s schema, something like Fivetran is probably worth a look.
Most importantly, both scalability and productivity are boosted by following the rules I’m proposing here. Single responsibility, immutable datasets, schema on write and so on all help to improve predictability and separate concerns, which in turn makes implementation and maintenance easier.
Does it work?
So, I’m sure the only question you have left is “did it work?”.
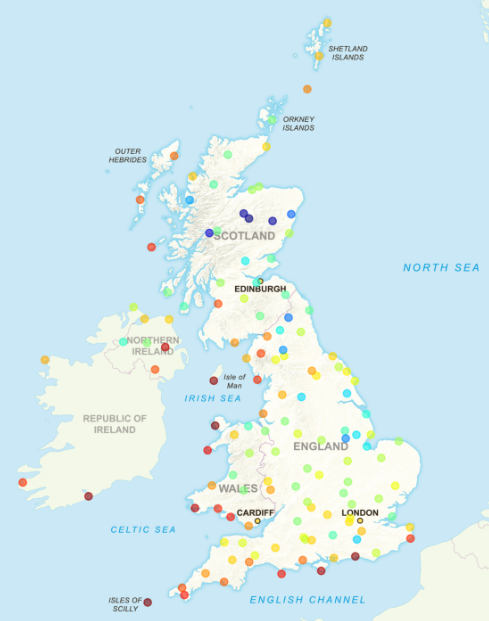
Well, it did! I coded this almost a year ago then changed jobs and pretty much forgot about it. When I decided to write this article, I checked in and found that it was running fine, having gather data every day all year. All the charts and maps in on this page use data collected by the World’s Simplest Data Pipeline.
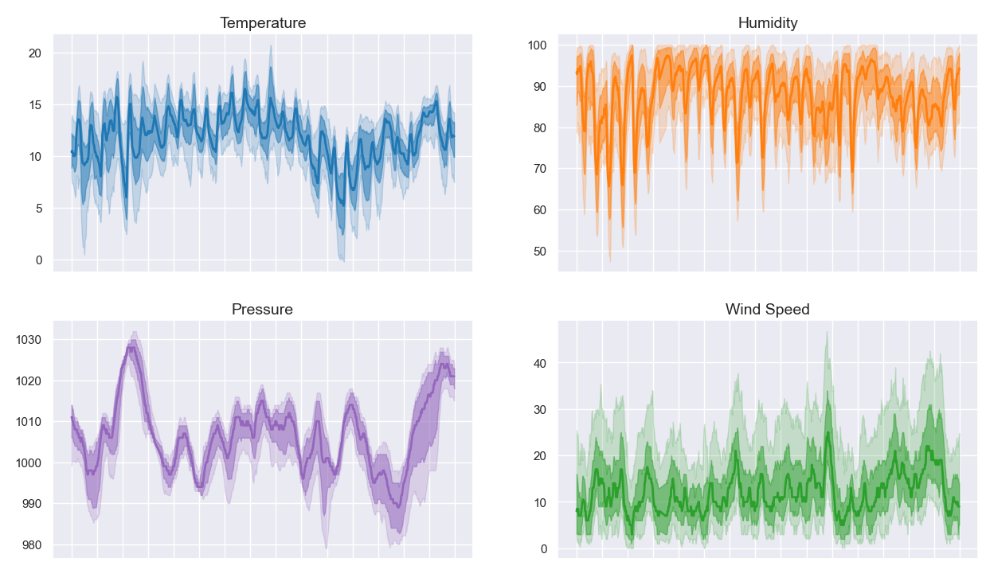
The data is however a bit messy, with missing values, a very basic schema and some duplicates which have to be coded around. This is the nature of data ingest systems. In an upcoming blog I’ll write about how to take the next step, from Data as a Capability to Data as an Asset and a warehouse full of lovely data models.
If you’re still here, why not find out how I’d do this in real time or read some general thoughts on Data Strategy.