One for the Road
December 12, 2018
This is the fourth part of my not-so-mini blog mini-series on Kafka, KSQL and transforming event data into models.
We’re reaching the closing stages of development of our Beer Festival system. We can load streaming and batch data, process, join and aggregate it and generate some cool-looking charts that update in real time…
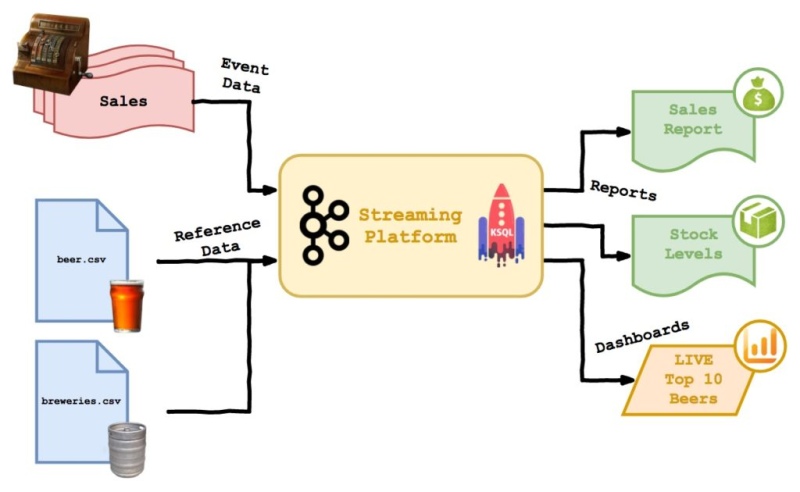
Two parts of the system are yet to be developed: loading brewery data and monitoring stock levels. While implementing them, we’re going to look at…
- Loading CSV data with Kafka Connect
- Validating data and handling bad rows
- Pushing data into an old school relational database
Breweries
In order to give the award for Best Selling Brewery, as the chairperson of the Beer Festival awards committee, I want to see a breakdown of sales by brewery.
First job is to load the data, which I’ll do with Kafka Connect. I guess I could have written another Scala app to do the load, but this time I wanted to test out some of the more standard tools for the job. Here we’ll use README in git.
Once you have dowloaded, compiled and installed SpoolDir you’ll need to create a Source config and post it via REST to start it. Here’s the config I ended up with:
{
"name": "csv-source-breweries",
"config": {
"value.schema": "{\"name\":\"com.github.jcustenborder.kafka.connect.model.Value\",\"type\":\"STRUCT\",\"isOptional\":false,\"fieldSchemas\":{\"row\":{\"type\":\"STRING\",\"isOptional\":false},\"name\":{\"type\":\"STRING\",\"isOptional\":false},\"city\":{\"type\":\"STRING\",\"isOptional\":true},\"state\":{\"type\":\"STRING\",\"isOptional\":true}}}",
"error.path": "/home/dan/csv/error",
"input.path": "/home/dan/csv/source",
"key.schema": "{\"name\":\"com.github.jcustenborder.kafka.connect.model.Key\",\"type\":\"STRUCT\",\"isOptional\":false,\"fieldSchemas\":{\"row\":{\"type\":\"STRING\",\"isOptional\":false}}}",
"finished.path": "/home/dan/csv/finished",
"halt.on.error": "false",
"topic": "breweries",
"tasks.max": "1",
"connector.class": "com.github.jcustenborder.kafka.connect.spooldir.SpoolDirCsvSourceConnector",
"input.file.pattern": "^.*.csv$",
"csv.first.row.as.header": true
}
}
It’s quite cool that we can impose a schema on the CSV as it’s loaded. For one thing, it means the data goes into Kafka in AVRO format, which saves us some work. Secondly, it allows some rudimentary error handling, should rows in the file be weirdly formatted. However, in a production system, it may make sense to load both good and bad rows and transform/validate them within Kafka… more on this later.
Once SpoolDir’s up and running (like I said, check the README for details) you can throw the breweries.csv file into the input directory and, as if by magic, you have data in the breweries topic.
ksql> create stream brewery_stream with (kafka_topic='breweries', value_format='avro');
ksql> select row, name, state, city from brewery_stream limit 4;
0 | NorthGate Brewing | MN | Minneapolis
1 | Against the Grain Brewery | KY | Louisville
2 | Jack's Abby Craft Lagers | MA | Framingham
3 | Mike Hess Brewing Company | CA | San Diego
Now we can create a brewery table over the top of the data using the same tricks as in Part 2. Note that, because I loaded the CSV data with the ‘row’ column, we need to rename it to ‘id’:
ksql> create stream brewery_stream_with_key \
with (kafka_topic='brewery_stream_with_key', value_format='avro') \
as select row as id, name, state, city from brewery_stream \
partition by id;
ksql> create table brewery_table with (kafka_topic='brewery_stream_with_key', value_format='avro', key='id');
Now we have the breweries loaded, let’s join the breweries data to our beer and sales data and see if we can show the top 10 breweries. The steps are:
- Drop and recreate the ```live_beer_sales``` stream from the last post, to add the ```brewery_id```.
- Using another new stream ```live_beer_sales_stringified```, convert the brewery_id to a string.
- Join to breweries in stream ```live_beer_brewery_sales```. Ideally, we'd have just done a double join to 'beers' and 'breweries' in one stream definition, but right now KSQL doesn't support that.
- Finally, create ```brewery_league_table``` with the aggregation.
ksql> drop stream live_beer_sales;
ksql> create stream live_beer_sales \
with (kafka_topic='live_beer_sales', value_format='avro') \
as select bar, price, name, abv, brewery_id from live_sales LS \
join beer_table BT on (LS.beer_id = BT.id);
ksql> create stream live_beer_sales_stringified \
with (kafka_topic='live_beer_sales_stringified', value_format='avro') \
as select bar, price, name, abv, cast(brewery_id as VARCHAR) as brewery_id \
from live_beer_sales;
ksql> create stream live_beer_brewery_sales \
with (kafka_topic='live_beer_brewery_sales', value_format='avro') \
as select bar, price, bs.name, abv, br.name as brewery, city, state \
from live_beer_sales_stringified bs \
join brewery_table br on (bs.brewery_id = br.id);
create table brewery_league_table \
with (kafka_topic='brewery_league_table', value_format='avro') \
as select brewery, city, state, sum(price) as sales \
from live_beer_brewery_sales group by brewery, city, state;
And given that we did all that work in KSQL, it seems only right that I quickly knocked up another web chart to show the winners:

Handling Dirty Data
**BUG REPORT: ** The 'breweries.csv' file is manually generated, and as a result contains some invalid rows. Yesterday a bad row prevented loading of the whole dataset. In future, bad rows should be filtered and quarantined while good rows continue to be loaded.
Having run data engineering teams for a long time, I can assure you that bugs like this are an eternal constant. Machine generated data is great - even when it arrives billions of rows at a time. Reference data is not so great because it is often touched by unreliable, biological parts of the process. Here is some bad data I added to the breweries file to simulate some common issues:
555,Ukiah Brewing Company,Ukiah, CA
556,Butternuts Beer and Ale,Garrattsville, NY
557,Sleeping Lady Brewing Company,Anchorage, AK
,
558,Dodgy Brewery,,
55nine,Brew-o-rama,New York, NY
560,,,
The quick brown fox jumped over the lazy pint
The last six lines are decidedly dodgy. Some violate the schema (missing values, wrong column count) and one has an invalid row number: ‘55nine’; This one wouldn’t actually break the schema, because we load the column as a string to use as the Kafka key - so let’s say it violates business rules.
With the Kafka Connect ingest solution, the schema violation errors will cause the whole file to be rejected and moved to the “error” folder. In some cases this is what we want - but there are many reasons why it might not be:
- The rows in the file might be unrelated and important - so we might want to load those which worked ASAP and deal with the bad ones later.
- Having the errored rows in Kafka may allow us to develop a better process for error reporting, monitoring and error correction.
- Validation might involve other data in Kafka somehow (joins etc).
- As much of the data flow as possible is safe within Kafka - with less files hanging around in random locations.
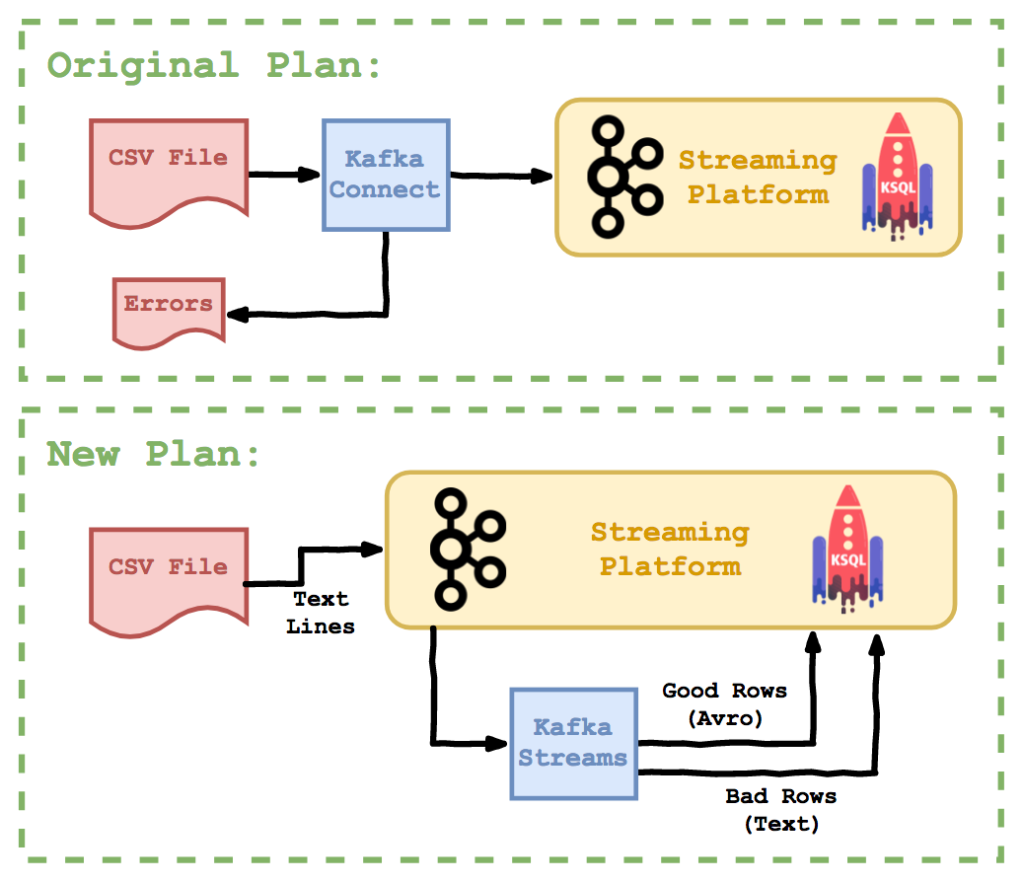
Loading the CSV file is now so simple it’s almost embarrassing - we can just use the console producer (though in real life you might still use a basic Kafka Connect job):
$ kafka-console-producer --broker-list localhost:9092 --topic raw_brewery_text < breweries.csv
Kafka streams, which we’ll use to do the brewery validation task, is a library of functions to make interacting with Kafka easy. It handles all the semantics of consuming and producing messages for you. It’s horizontally scalable and pretty lightweight.
The code can be found in full on my github and is pretty concise. The key bit is the setup of the streams themselves, which is shown below. If you’re going to code a Kafka streams app yourself, pay attention to the implicit serdes (serialiser/deserialisers) which are defined higher up the object definition. These had me puzzled for hours! Anyway, the code…
// Get the lines
val builder = new StreamsBuilder()
val textLines: KStream[String, String] = builder.stream[String, String]("raw_brewery_text")
// Validate and branch
val Array(good, bad) = textLines.branch(
(_, v) => validate(v),
(_, _) => true
)
// Send the good rows to the good topic
good.flatMap((_, v) => toAvro(v)).to("brewery_rows_good")
// ...and the bad to the bad
bad.to("brewery_rows_bad")
// Start the streams
val streams: KafkaStreams = new KafkaStreams(builder.build(), config)
streams.cleanUp()
streams.start()
Once the code has been running for a while and brewery data piped into the input topic, the output is split as follows:
ksql> select * from brewery_rows_good limit 5;
1544427745358 | 0 | 0 | NorthGate Brewing | Minneapolis | MN
1544427745358 | 1 | 1 | Against the Grain Brewery | Louisville | KY
1544427745358 | 2 | 2 | Jack's Abby Craft Lagers | Framingham | MA
1544427745358 | 3 | 3 | Mike Hess Brewing Company | San Diego | CA
1544427745358 | 4 | 4 | Fort Point Beer Company | San Francisco | CA
ksql> print 'brewery_rows_bad';
Format:STRING
10/12/18 07:47:03 GMT , NULL , row,name,city,state
10/12/18 07:47:03 GMT , NULL , ,
10/12/18 07:47:03 GMT , NULL , 558,Dodgy Brewery,,
10/12/18 07:47:03 GMT , NULL , 55nine,Brew-o-rama,New York, NY
10/12/18 07:47:03 GMT , NULL , 560,,,
10/12/18 07:47:03 GMT , NULL ,
10/12/18 07:47:03 GMT , NULL , The quick brown fox jumped over the lazy pint
It’s easy to imagine how you could create a process for handling these dodgy input rows with Kafka, especially now we know they are isolated from the good rows, which loaded normally.
Loading Master Data to a DB
In order to have consistent validation logic for loading beer and brewery reference data from CSV files, as data guardian I want to push master data from Kafka into our MySQL 'warehouse', rather than having a separate ETL for that.
Sounds like a sensible requirement - except maybe the bit about using MySQL as a data warehouse ;) If we loaded reference data differently in the streaming and batch parts of our data estate it may lead to inconsistencies and confusion - plus we’d need to maintain two bits of code.
Kafka Connect can be set up to write to a MySQL database directly from a topic. This can be done in two modes - for event/timeseries data you can do a pure ‘insert’ where key clashes are rejected; for reference/master data you can ‘upsert’ which will insert or update based on a nominated key. Here’s some example config:
{
"name": "jdbc_sink_mysql_beers",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"topics": "beer_stream_with_key",
"connection.url": "jdbc:mysql://localhost:3306/beerfest?user=you&password=password",
"auto.create": "true",
"pk.mode": "record_value",
"pk.fields": "ROW",
"insert.mode": "upsert",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://localhost:8081"
}
}
Key configuration items to be aware of are:
- ```insert.mode``` - we want to insert new or update existing records
- ```auto.create``` - create the table if it doesn't exist
- ```pk.mode``` - take the primary key from the message value
- ```pk.fields``` - use the 'ROW' field as primary key (case sensitive, beware!)
You can submit and start the job using the confluent CLI:
$ confluent load jdbc_sink_mysql_beers -d kafka-to-mysql.json
There’s not much to show here, but once the connector is running (submitted as below) then all of a sudden you have a table with magically updating beer data in MySQL. Check it out:
mysql> select * from beer_stream_with_key where name like "Pub Beer";
+------+------------+---------------------+--------+-----+------+------+----------+
| ABV | BREWERY_ID | STYLE | OUNCES | ROW | ID | IBU | NAME |
+------+------------+---------------------+--------+-----+------+------+----------+
| 0.05 | 408 | American Pale Lager | 12 | 0 | 1436 | NULL | Pub Beer |
+------+------------+---------------------+--------+-----+------+------+----------+
mysql> select count(*) from beer_stream_with_key;
+----------+
| count(*) |
+----------+
| 2410 |
+----------+
I’m kind of blown away by how easy that was. Much easier than writing an ETL, right? It also means that we now have reliable, synchronised master data in the streaming and batch sides of our lambda architecture. Boom!
Stock Level Management
In order to ensure I purchase the correct barrels of tasty tasty beer, as the Head of Cellar Services, I want live sales to be sent to my stock control system, which is backed by a MySQL database.
This should be pretty simple - we just need a sensible key for the destination table. A sensible choice is a compound key with timestamp, bar number and beer id. Here I create a stream with the timestamp available in the message payload (in real life you probably have a better timestamp to use!)
ksql> create stream outgoing_sales with (kafka_topic='outgoing_sales', value_format='avro') as select beer_id, bar, price, rowtime as ts from live_sales;
Same idea as above for writing to MySQL. Here are the config options I changed:
{
"name": "jdbc_sink_mysql_sales",
"config": {
// ...
"topics": "outgoing_sales",
"auto.create": "true",
"pk.mode": "record_value",
"pk.fields": "TS,BAR,BEER_ID",
"insert.mode": "insert",
"consumer.auto.offset.reset": "earliest"
// ...
}
}
And off we go! Just to prove that it works, here’s an example join to the beer table:
mysql> describe outgoing_sales;
+---------+------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+------------+------+-----+---------+-------+
| BAR | int(11) | NO | PRI | NULL | |
| PRICE | int(11) | YES | | NULL | |
| BEER_ID | int(11) | NO | PRI | NULL | |
| TS | bigint(20) | NO | PRI | NULL | |
+---------+------------+------+-----+---------+-------+
4 rows in set (0.01 sec)
mysql> select name, sum(price) \
from outgoing_sales \
join beer_stream_with_key on (beer_id = id) \
group by name \
order by sum(price) desc \
limit 5;
+---------------------------+------------+
| name | sum(price) |
+---------------------------+------------+
| Nonstop Hef Hop | 9 |
| Longboard Island Lager | 8 |
| Black Iron India Pale Ale | 7 |
| Keeper (Current) | 7 |
| Pub Beer | 6 |
+---------------------------+------------+
5 rows in set (0.33 sec)
So now we have stock data flowing to the SQL database, which will enable our BI team to build the reports and processes they need there.
“Sorry that one’s off mate…”
In order to prevent bar staff selling cloudy beers from barrels which are almost empty, as the head of beer quality services, I want to take stock level data from the stock control system in MySQL and push it to the beer sales system Kafka.
This last story demonstrates how we can use a traditional relational database as a source of streaming data in Kafka. Essentially we’re just wiring up Kafka Connect the other way round. The really cool thing here is that this enables us to turn update statements in the database into change events in Kafka. Here’s the table we’re reading from:
mysql> describe stock_levels;
+-----------------+------------+------+-----+-------------------+-----------------------------------------------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+------------+------+-----+-------------------+-----------------------------------------------+
| beer_id | varchar(8) | NO | PRI | NULL | |
| remaining_pints | int(11) | YES | | NULL | |
| create_ts | timestamp | YES | | CURRENT_TIMESTAMP | DEFAULT_GENERATED |
| update_ts | timestamp | YES | | CURRENT_TIMESTAMP | DEFAULT_GENERATED on update CURRENT_TIMESTAMP |
+-----------------+------------+------+-----+-------------------+-----------------------------------------------+
4 rows in set (0.00 sec)
Note that the table needs auto-generated timestamp columns which Kafka Connect can use to find new or changed rows. These are then referenced in the Kafka Connect config:
{
"name": "jdbc_source_mysql_stock_levels",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://localhost:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://localhost:8081",
"connection.url": "jdbc:mysql://localhost:3306/beerfest?user=dant&password=password",
"table.whitelist": "stock_levels",
"mode": "timestamp",
"timestamp.column.name": "update_ts",
"validate.non.null": "false",
"topic.prefix": "mysql_"
}
}
The next bit is hard to show in a blog post, but the following two snippets occurred in parallel. As I inserted and updated rows in my source table, the changes were pushed to the topic in Kafka, as if by magic!
mysql> insert into stock_levels (beer_id, remaining_pints) values ("0", 45);
Query OK, 1 row affected (0.01 sec)
mysql> insert into stock_levels (beer_id, remaining_pints) values ("1", 38);
Query OK, 1 row affected (0.03 sec)
mysql> update stock_levels set remaining_pints=44 where beer_id = "0";
Query OK, 1 row affected (0.07 sec)
The three rows in the stream appeared as I executed the insert and update statements above…
ksql> create stream stock_levels with (kafka_topic='mysql_stock_levels', value_format='avro');
ksql> select * from stock_levels;
1544554098590 | null | 0 | 45 | 1544554094000 | 1544554094000
1544554158522 | null | 1 | 38 | 1544554157000 | 1544554157000
1544554198579 | null | 0 | 44 | 1544554094000 | 1544554197000
This is an incredibly neat way to pipe data out of a relational database and into a streaming system. Unlike traditional backup/restore or periodic table dumping techniques, you get every change, as it happens. The other good thing is that you don’t miss anything - imagine doing an hourly dump of a DB table, you’d miss all updates within each hour except the last - with Kafka Connect you get every single change.
“Drink up, we’re closed!”
This post has been a long one, but hopefully has demonstrated the power of Kafka Connect and Kafka Streams. It’s certainly got me thinking of better ways to integrate a streaming platform with traditional databases, ensuring that both stay updated with consistent data and that business logic and transforms are implemented just once.
We’ve also looked at two options for dealing with potentially messy data coming in from third parties - which is a huge drain on a Data team’s time and energy if handled in a bespoke-ETL fashion.
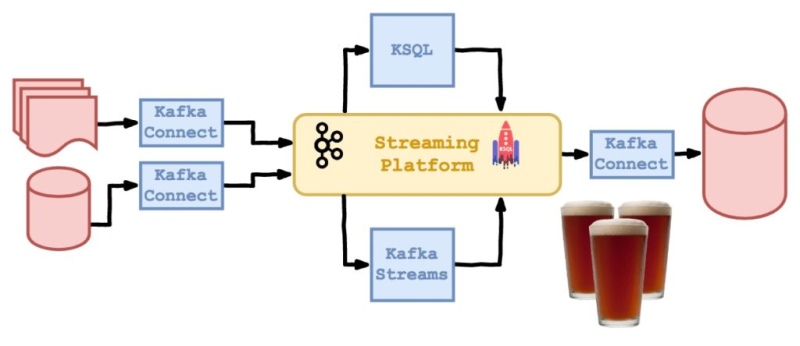
In this blog series I set out to investigate and hopefully illustrate a modern solution for integrating streaming event data and warehoused model data. Though there are many things I glossed over - subjects like DevOps and production hardening were notably overlooked for example - I think I at least managed to convince myself!
Cheers!