Moving data around with Apache NiFi
July 4, 2016
I’ve been playing around with Apache NiFi in my spare time (on the train) for the last few days. I’m rather impressed so far so I thought I’d document some of my findings here.
NiFi is a tool for collecting, transforming and moving data. It’s basically an ETL with a graphical interface and a number of pre-made processing elements. Stuffy corporate architects might call it a “mediation platform” but for me it’s more like ETL coding with Lego Mindstorms.
This is not a new concept - Talend have been around for a while doing the same thing. Something just never worked with talend though, perhaps they abstracted at the wrong level or prerhaps they tried to be too general. Either way, the difference between Talend and NiFi is like night and day!
Garmin Track Data
So I don’t have access to a huge amount of “big data” on my laptop, and I’ve done articles on MOT and National Rail data recently, so I decided to use a couple of gigs of Garmin Track data to test NiFi. The track data is a good test as it’s XML: exactly the sort of data you don’t want going into your big data system and therefore exactly the right use-case for NiFi.
<?xml version="1.0" encoding="UTF-8"?>
<TrainingCenterDatabase xsi:schemaLocation="blah blah blah">
<Activities>
<Activity Sport="Biking">
<Id>2015-04-06T13:26:53.000Z</Id>
<Lap StartTime="2015-04-06T13:26:53.000Z">
<TotalTimeSeconds>3159.267</TotalTimeSeconds>
<DistanceMeters>12408.35</DistanceMeters>
<MaximumSpeed>8.923999786376953</MaximumSpeed>
<Calories>526</Calories>
<Track>
<Trackpoint>
<Time>2015-04-06T13:26:53.000Z</Time>
<Position>
<LatitudeDegrees>51.516099665910006</LatitudeDegrees>
<LongitudeDegrees>-1.244160421192646</LongitudeDegrees>
</Position>
<AltitudeMeters>91.80000305175781</AltitudeMeters>
<DistanceMeters>0.0</DistanceMeters>
</Trackpoint>
<!-- ... -->
<Trackpoint>
<Time>2015-04-06T13:26:54.000Z</Time>
<Position>
<LatitudeDegrees>51.516099665910006</LatitudeDegrees>
<LongitudeDegrees>-1.244160421192646</LongitudeDegrees>
</Position>
<AltitudeMeters>91.80000305175781</AltitudeMeters>
<DistanceMeters>0.0</DistanceMeters>
</Trackpoint>
</Track>
</Lap>
</Activity>
</Activities>
</TrainingCenterDatabase>
The only data in the file I’m particularly interested in is “where I went”. The calorie counts and suchlike are great on the day, but don’t tell us much after the fact. So, the plan is to extract the Latitude and Longitude fields from the Track element. Everything else is just noise.
Working with NiFi
NiFi uses files as the fundamental unit of work. Files are collected, processed and output by a flow of processors. Files can be transformed, split or combined into more files as needed. The links between processors act as buffers, queuing files between processing stages.
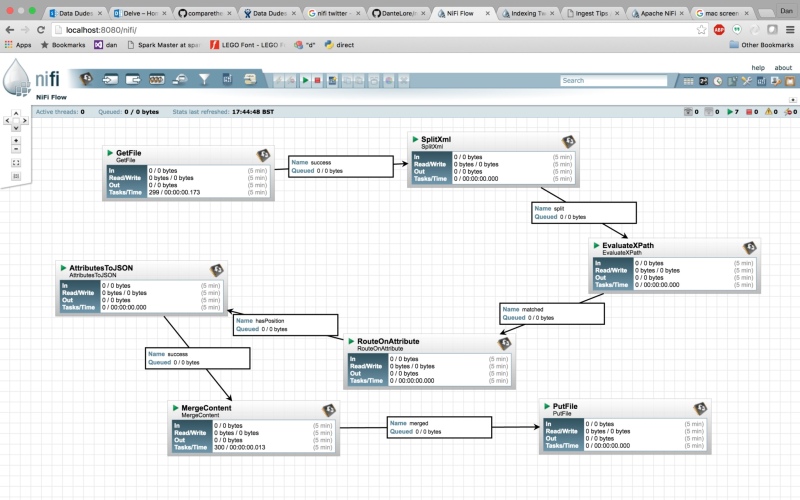
The first part of the flow gathers the XML files from their location on disk (since Garmin charge an obcene amount for access to your own data via their API), splits the XML into multiple files then uses a simple XPath expression to extract out the Latitude and Longitude.
A GetFile processor reads whole XML file. Next a SplitXml processor takes the XML in each file and splits into multiple files by chopping the XML at a secified level (in this case 5) making a set of new files, one per TrackPoint element. Following that, an EvaluateXPath processor extracts the Lat and Long and stores them as attributes on each individual file.
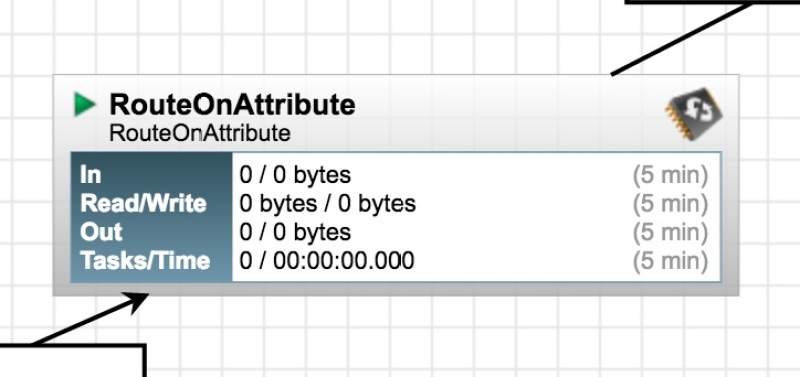
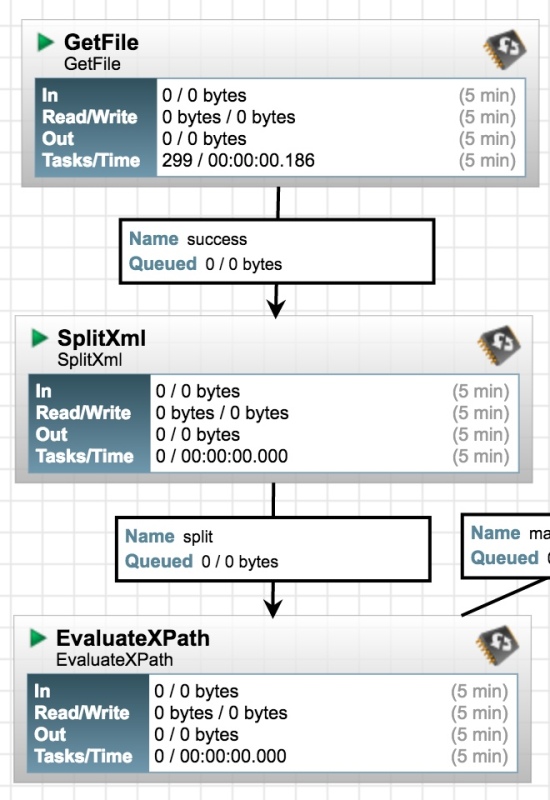
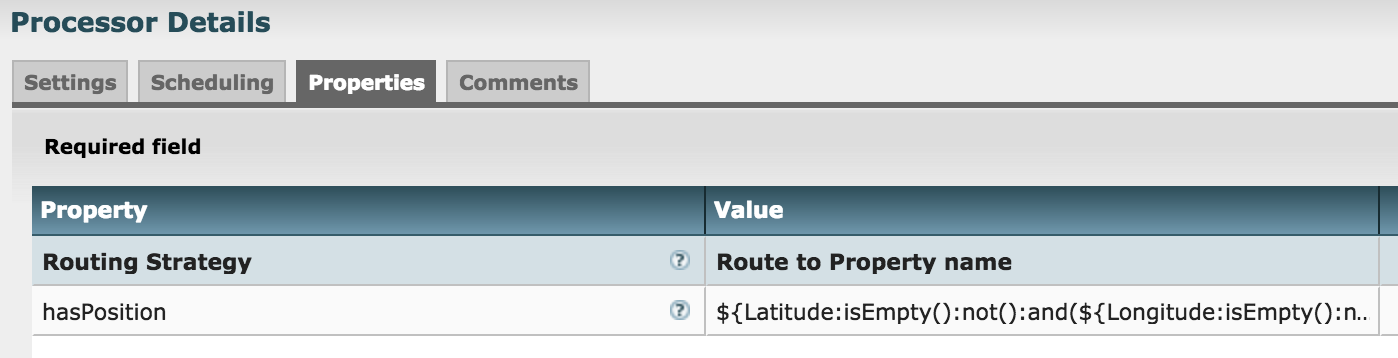
The rather naive XML split will return all elements at the specified level within the document tree. XPath is fine with that, it will either match a Lat and Long or it won’t. The issue is that we’ll end up with a large number of files where no location was found. The RouteOnAttribure process can be used to discard all these empty files. Settings shown below:
So, now we have a stream of files (actually empty files!) each of which is decorated with attribues for Latitude and Longitude. The last part of the flow is all about saving these to a file.
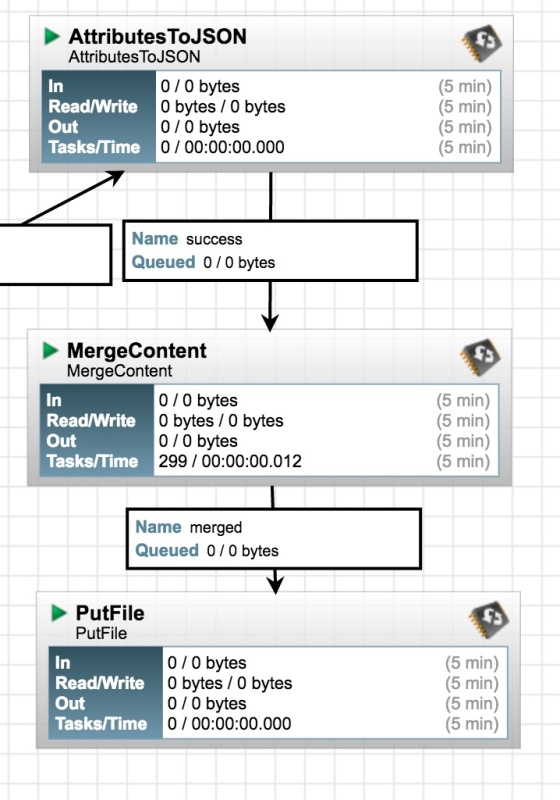
The first processor in this part of the flow takes the attributes of each file and converts them to JSON, dropping the JSON string into the file body. We could just save the file at this stage, but that would be a lot of files. The second block takes a large number of single-record JSON files and joins them together to create a single line-delimited JSON file which culd be read by something like Storm or Spark. I had all sorts of trouble escaping a carriage return within the MergeContent block, so in the end I stored a carriage return character in a file called “~/newLine.txt” and referenced that in the processor settings. Not pretty, but it works. The last block in the flow saves files - not much more to say about that!
Drawbacks and/or Benefits
It took a little over one train journey to get this workflow set up and working and most of that was using Google! Compared to using Talend for the same job it was an abslute dream!
Perhaps the only shortcoming of the system is that it can’t do things like aggregations - so I can’t convert the stream of locations to a “binned” map wit counts per 50x50m square for example. De-duplication doesn’t seem possible either… but if you think about how these operations would have to be implemented, you realise how complicated and resource hungry they would make the system. If you want to do aggregations, de-duplication and all that jazz, you can plug NiFi into Spark Streaming.
Most data integration jobs I’ve seen are pretty simple: moving data from a database table to HDFS, pulling records from a REST API, downloading things from a dropzone… and for all of these jobs, NiFi is pretty much perfect. It has the added benefit that it can be configured and maintaned by non-technical people, which makes it cheaper to integrate into a workflow.
I like it!