Behaviour Driven Spark
August 8, 2016
Spark is a big deal these days, people are using this for all sorts of exciting data wrangling. There’s a huge trend for ease of use within the Spark community and with tools like Apache Zeppelin coming onto the scene the barrier to entry is very low. This is all good stuff: open source projects live and die in the first half an hour of use. New users need to get something cool working quickly or they’ll get bored and wander off…
But for those of us who got past Hello World some time ago and are now using Spark as the basis of large and important projects there’s also the chance to do things right. In fact, since Spark is based on a proper language (Scala, not R or python please!) it’s a great chance to bring some well established best practices into a world where uncontrolled script hackers have held sway for too long!
Check out the source for this article on my GitHub: https://github.com/DanteLore/bdd-spark

Behaviour Driven Development, or BDD, is a bit like unit testing. Like unit testing done by an experienced master craftsman. On the surface they look the same - you write some “test” code which calls your production code with known inputs and checks the outputs are what you want them to be. It can be run from your IDE and automated in your CI build because it uses the same runner as your unit tests under the hood.
For me, TDD and BDD differ in these two critical ways: BDD tests at the right level; because you’re writing “Specifications” in pseudo-English not “Tests” in code you feel less inclined to test every function of every class. You test at the external touch-points of your app (load this data, write to this table, show this on the UI), which makes your tests less brittle and more business oriented. Which leads to the second difference: BDD specs are written in Cucumber, a language easily accessible to less techie folks like testers, product owners and stakeholders. Because Cucumber expresses business concepts in near-natural language, even your Sales team have a fighting chance of understanding it… well, maybe.
Project Setup
Before we can crack on and write some Cucumber, there is some setup to be done in the project. I am using IntelliJ, but these steps should work for command line SBT also.
First job, get build.sbt set up for Spark and BDD:
name := "spark-bdd-example"
version := "1.0"
scalaVersion := "2.10.6"
libraryDependencies ++= Seq(
"log4j" % "log4j" % "1.2.14",
"org.apache.spark" %% "spark-core" % "1.6.0",
"org.apache.spark" %% "spark-sql" % "1.6.0",
"org.apache.spark" %% "spark-mllib" % "1.6.0",
"org.json4s" %% "json4s-jackson" % "3.2.7",
"info.cukes" % "cucumber-core" % "1.2.4" % "test",
"info.cukes" %% "cucumber-scala" % "1.2.4" % "test",
"info.cukes" % "cucumber-jvm" % "1.2.4" % "test",
"info.cukes" % "cucumber-junit" % "1.2.4" % "test",
"junit" % "junit" % "4.12" % "test",
"org.scalatest" %% "scalatest" % "2.2.4" % "test"
)
For this example I am wrapping Spark up in an object to make it globally available and save me mocking it out “properly”. In a production app, where you need tighter control of the options you pass to spark, you might want to mock it out and write a “Given” to spin Spark up. Here’s my simple object in Spark.scala:
object Spark {
val conf = new SparkConf()
.setAppName("BDD Test")
.setMaster("local[8]")
.set("spark.default.parallelism", "8")
.set("spark.sql.shuffle.partitions", "8")
val sc = new SparkContext(conf)
LogManager.getRootLogger.setLevel(Level.ERROR)
val sqlContext = new SQLContext(Spark.sc)
sqlContext.setConf("spark.sql.shuffle.partitions", "8")
}
If using IntelliJ, like me, you’ll also need a test class to run your cucumber. Mine’s in Runtests.scala. Right click on this and select “Run tests” from the context menu and it’ll run the tests.
@RunWith(classOf[Cucumber])
class RunTests extends {
}
If using the command line, add this line to project/plugins.sbt:
addSbtPlugin("com.waioeka.sbt" % "cucumber-plugin" % "0.0.3")
And these to build.sbt:
enablePlugins(CucumberPlugin)
CucumberPlugin.glue := ""
First Very Simple Example
Here’s the first bit of actual cucumber. We’re using it for a contrived word-counting example here. The file starts with some furniture, defining the name of the Feature and some information on it’s purpose, usually in the format In order to achieve some business aim, As the user or beneficiary of the feature, I want some feature.
[code lang=“gherkin”] Feature: Basic Spark
In order to prove you can do simple BDD with spark As a developer I want some spark tests
Scenario: Count some words with an RDD When I count the words in “the complete works of Shakespeare” Then the number of words is ‘5’ [/code]
The rest of the file is devoted to a series of Scenarios, these are the important bits. Each scenario should test a very specific behaviour, there’s no limit to the number of scenarios you can define, so take the opportunity to keep them focussed. As well as a descriptive name, each scenario is made of a number of steps. Steps can be Givens, Whens or Thens.
- *"**Given** some precondition*": pre-test setup. Stuff like creating a mock filesystem object, setting up a dummy web server or initialising the Spark context
- *"**When** some action*": call the function you're testing; make the REST call, whatever
- *"**Then** some test*": test the result is what you expected
Step Definitions
Each step is bound up to a method as shown in the “Steps” class below. When the feature file is “executed” the function bound to each step is executed. You can pass parameters to steps as shown here with the input string and the expected number of words. You can re-use steps in as many scenarios and features as you like. Note that the binding between steps and their corresponding functions is done with regular expressions.
class SparkSteps extends ScalaDsl with EN with Matchers {
When("""^I count the words in "([^"]*)"$"""){ (input:String) =>
Context.result = Spark.sc.parallelize(input.split(' ')).count().toInt
}
Then("""^the number of words is '(\d+)'$"""){ (expected:Int) =>
Context.result shouldEqual expected
}
}
The Context
The Context object here is used to store things… any variables needed by the steps. You could use private fields on the step classes to achieve this, but you’d quickly encounter problems when you began to define steps over multiple classes.
object Context {
var result = 0
}
I don’t particularly like using a Context object like this, as it relies on having vars, which isn’t nice. If you know a better way, please do let me know via the comments box below!
Data Tables
So the word counting example above shows how we can do BDD with spark - we pass in some data and check the result. Great! But it’s not very real. The following example uses Spark DataFrames and Cucumber DataTables to do something a bit more realistic:
Scenario: Joining data from two data frames to create a new data frame of results
Given a table of data in a temp table called "housePrices"
| Price:Int | Postcode:String | HouseType:String |
| 318000 | NN9 6LS | D |
| 137000 | NN3 8HJ | T |
| 180000 | NN14 6TN | S |
| 249000 | NN14 6TN | D |
And a table of data in a temp table called "postcodes"
| Postcode:String | Latitude:Double | Longitude:Double |
| NN9 6LS | 51.1 | -1.2 |
| NN3 8HJ | 51.2 | -1.1 |
| NN14 6TN | 51.3 | -1.0 |
When I join the data
Then the data in temp table "results" is
| Price:Int | Postcode:String | HouseType:String | Latitude:Double | Longitude:Double |
| 318000 | NN9 6LS | D | 51.1 | -1.2 |
| 137000 | NN3 8HJ | T | 51.2 | -1.1 |
| 180000 | NN14 6TN | S | 51.3 | -1.0 |
| 249000 | NN14 6TN | D | 51.3 | -1.0 |
You only need to write the code to translate the data tables defined in your cucumber to data frames once. Here’s my version:
class ComplexSparkSteps extends ScalaDsl with EN with Matchers {
def dataTableToDataFrame(data: DataTable): DataFrame = {
val fieldSpec = data
.topCells()
.map(_.split(':'))
.map(splits => (splits(0), splits(1).toLowerCase))
.map {
case (name, "string") => (name, DataTypes.StringType)
case (name, "double") => (name, DataTypes.DoubleType)
case (name, "int") => (name, DataTypes.IntegerType)
case (name, "integer") => (name, DataTypes.IntegerType)
case (name, "long") => (name, DataTypes.LongType)
case (name, "boolean") => (name, DataTypes.BooleanType)
case (name, "bool") => (name, DataTypes.BooleanType)
case (name, _) => (name, DataTypes.StringType)
}
val schema = StructType(
fieldSpec
.map { case (name, dataType) =>
StructField(name, dataType, nullable = false)
}
)
val rows = data
.asMaps(classOf[String], classOf[String])
.map { row =>
val values = row
.values()
.zip(fieldSpec)
.map { case (v, (fn, dt)) => (v, dt) }
.map {
case (v, DataTypes.IntegerType) => v.toInt
case (v, DataTypes.DoubleType) => v.toDouble
case (v, DataTypes.LongType) => v.toLong
case (v, DataTypes.BooleanType) => v.toBoolean
case (v, DataTypes.StringType) => v
}
.toSeq
Row.fromSeq(values)
}
.toList
val df = Spark.sqlContext.createDataFrame(Spark.sc.parallelize(rows), schema)
df
}
Given("""^a table of data in a temp table called "([^"]*)"$""") { (tableName: String, data: DataTable) =>
val df = dataTableToDataFrame(data)
df.registerTempTable(tableName)
df.printSchema()
df.show()
}
}
Likewise, you can define a function to compare the output data frame with the “expected” data from the cucumber table. This is a simple implementation, I have seen some much classier versions which report the row and column of the mismatch etc.
Then("""^the data in temp table "([^"]*)" is$"""){ (tableName: String, expectedData: DataTable) =>
val expectedDf = dataTableToDataFrame(expectedData)
val actualDf = Spark.sqlContext.sql(s"select * from $tableName")
val cols = expectedDf.schema.map(_.name).sorted
val expected = expectedDf.select(cols.head, cols.tail: _*)
val actual = actualDf.select(cols.head, cols.tail: _*)
println("Comparing DFs (expected, actual):")
expected.show()
actual.show()
actual.count() shouldEqual expected.count()
expected.intersect(actual).count() shouldEqual expected.count()
}
Coverage Reporting
There’s a great coverage plugin for Scala which can easily be added to the project by adding a single line to plugins.sbt:
logLevel := Level.Warn
addSbtPlugin("com.waioeka.sbt" % "cucumber-plugin" % "0.0.3")
addSbtPlugin("org.scoverage" % "sbt-scoverage" % "1.3.5")
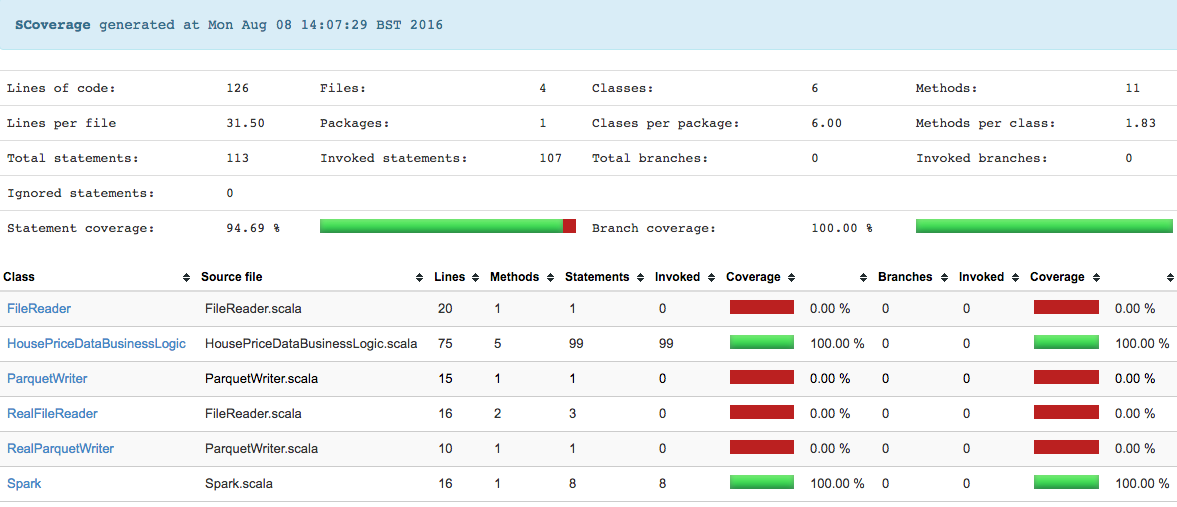
The report is generated with the following SBT command and saved to HTML and XML formats for viewing or ingest by a tool (like SonarQube).
$ sbt clean coverage cucumber coverageReport
...
[info] Written Cobertura report [/Users/DTAYLOR/Development/bdd-spark/target/scala-2.10/coverage-report/cobertura.xml]
[info] Written XML coverage report [/Users/DTAYLOR/Development/bdd-spark/target/scala-2.10/scoverage-report/scoverage.xml]
[info] Written HTML coverage report [/Users/DTAYLOR/Development/bdd-spark/target/scala-2.10/scoverage-report/index.html]
[info] Statement coverage.: 94.69%
[info] Branch coverage....: 100.00%
[info] Coverage reports completed
[info] All done. Coverage was [94.69%]
[success] Total time: 1 s, completed 08-Aug-2016 14:27:17
Conclusion
So, hopefully this long and rambling article has made one key point: You can use BDD to develop Spark apps. The fact that you should isn’t something anyone can prove, it’s just something you’ll have to take on faith!